
Claude Mythos Proves the AI-Persistent Threat Era Has Arrived
Anthropic couldn't safely release their most powerful model. That's not just a safety story. It's an adversarial roadmap. Claude Mythos is a step function in AI capability, for defenders and adversaries alike. Model hardening alone doesn't close that gap.


Anthropic's decision not to release Claude Mythos Preview publicly tells you more about the threat landscape than any benchmark does. Every capability they describe — a 27-year-old OpenBSD flaw found autonomously, a 16-year-old FFmpeg vulnerability that survived five million automated test runs, 181 working Firefox exploits generated in a single session — is also a specification for what a well-resourced adversary is building toward. We believe the Mythos model is being read primarily as a defensive milestone. It should also be read as an adversarial roadmap too.
For context: the model behind Glasswing scored 93.9% on SWE-bench Verified compared to 80.8% for Anthropic's previous flagship, on a benchmark testing real software engineering problems drawn from actual GitHub repositories. That is a fundamentally different capability level, and the discovery-to-exploitation window that once gave defenders weeks or months to respond now collapses to minutes. Project Glasswing deploys this capability defensively before adversaries can match it. The premise is sound. Our view is that the window it assumes is shorter than most security teams think.
The security community's response has been largely admiring: impressive, responsible, necessary. We'd add a fourth word: incomplete.
From APT to AiPT
For two decades, nation-state actors operated under the APT model, where the defining trait was patience: establish a foothold, move laterally, persist quietly, exfiltrate. The rare human expertise required to sustain these campaigns naturally constrained who could run them and at what scale.
AI changes that calculus. Where APT actors relied on expensive human expertise sustained over months, AiPTs — AI-powered Persistent Threats — replace that with autonomous orchestration that runs continuously, adapts in real time, and scales to any target: a new class of AI-driven, agentic cyberattack where autonomous engines plan, adapt, and execute campaigns at scale. The Villager framework our STAR team documented earlier this year is the first confirmed instance in the wild.
Villager, built by the Chinese-based group Cyberspike and published on PyPI, is an AI-native penetration testing framework structured as the successor to Cobalt Strike. For context: it accumulated 10,000 downloads within two months of release, at an average rate of 200 additional downloads every three days during our investigation. It integrates DeepSeek AI with containerized Kali Linux toolsets, uses a database of 4,201 system prompts to generate exploits in real time, and includes 24-hour self-destructing containers with randomized SSH ports to defeat forensic analysis. Any operator can submit a natural language objective and watch the framework decompose it into a full attack chain autonomously.
What Villager and Mythos Preview have in common is more important than what separates them. They represent two points on the same AiPT trajectory: one at the commodity end, one at the frontier. Three behaviors define the class across both:
- Autonomous campaign execution. AiPTs use task-based architectures where the AI decomposes a high-level objective, such as "find and exploit vulnerabilities in example.com," into a full reconnaissance-to-exploitation chain, executes each phase in sequence, recovers from failures, and verifies results without operator intervention. The attacker issues a goal; the framework handles the rest.
- Dynamic, context-driven adaptation. Where Cobalt Strike follows scripted playbooks, AiPTs select and pivot between tools based on what they discover. Villager automatically launches WPScan when it detects WordPress, shifts to browser automation when it finds an API endpoint, and chains results from each step into the next. As Straiker's STAR team noted: "This coordinated approach occurs organically through the GenAI's task planning, not through rigid programming."
- Dramatically lower barrier to entry. Mythos Preview found a FreeBSD remote code execution exploit for under $2,000 and under a day of processing time. Villager achieves multi-stage attack orchestration from a PyPI package anyone can install. The cost and expertise floor for sophisticated attacks is collapsing at both ends of the spectrum.
One detail in Anthropic's technical disclosure ties these two points together: "We did not explicitly train Mythos Preview to have these capabilities. Rather, they emerged as a downstream consequence of general improvements in code, reasoning, and autonomy." Mythos Preview became the most capable offensive AI security tool ever documented without being designed as one. Every future generation will be more capable still. The AiPT trajectory is not a product decision — it is a property of intelligence itself.
When Glasswing-Class Capability Reaches Adversarial Hands
Anthropic has restricted Mythos Preview to a coalition of founding partners spanning cloud infrastructure, enterprise security, and financial services — organizations with the resources and accountability to use it responsibly. That access policy is deliberate and well-considered. Exclusive access to frontier capability is also temporary.
This year, security firm Aisle demonstrated they could replicate Glasswing's vulnerability-finding results using older, publicly available models. Given the investments China, Russia, Iran, and North Korea have made in frontier AI development, Mythos-equivalent capabilities are a near-term certainty in adversarial hands. Three scenarios describe what becomes possible when that happens:
1. Targeting the model layer directly. Organizations deploying Claude or any frontier model in agentic workflows are running a high-value target. Prompt injection spiked 540% in 2025, the fastest-growing threat category in AI security. An adversary needs only one successful injection into your AI agent's context window to access everything that agent can reach. Straiker's own research makes this concrete: a single malicious email can trigger a zero-click agent chain that exfiltrates an entire Google Drive with no user interaction required.
2. Exploiting the agentic stack above the model. Security attention naturally concentrates on the model layer. The agentic applications running above it — tools, memory systems, orchestration layers, integrations — receive far less scrutiny and carry far more exposure. A sophisticated adversary with Mythos-level capability targets the tool-calling layer, the memory interface, or the integration logic, because the model's internal defenses become irrelevant once the attack lives above them.
3. Persistent enumeration of your AI attack surface. An adversary running continuous, low-cost scans against your AI deployment, probing each model update for regression vulnerabilities, is doing something categorically different from a discrete breach attempt. They are tracking a surface that evolves continuously and has never been fully characterized, maintaining a persistent adversarial relationship with your AI infrastructure rather than pursuing a defined exit.
The Immunity Myth
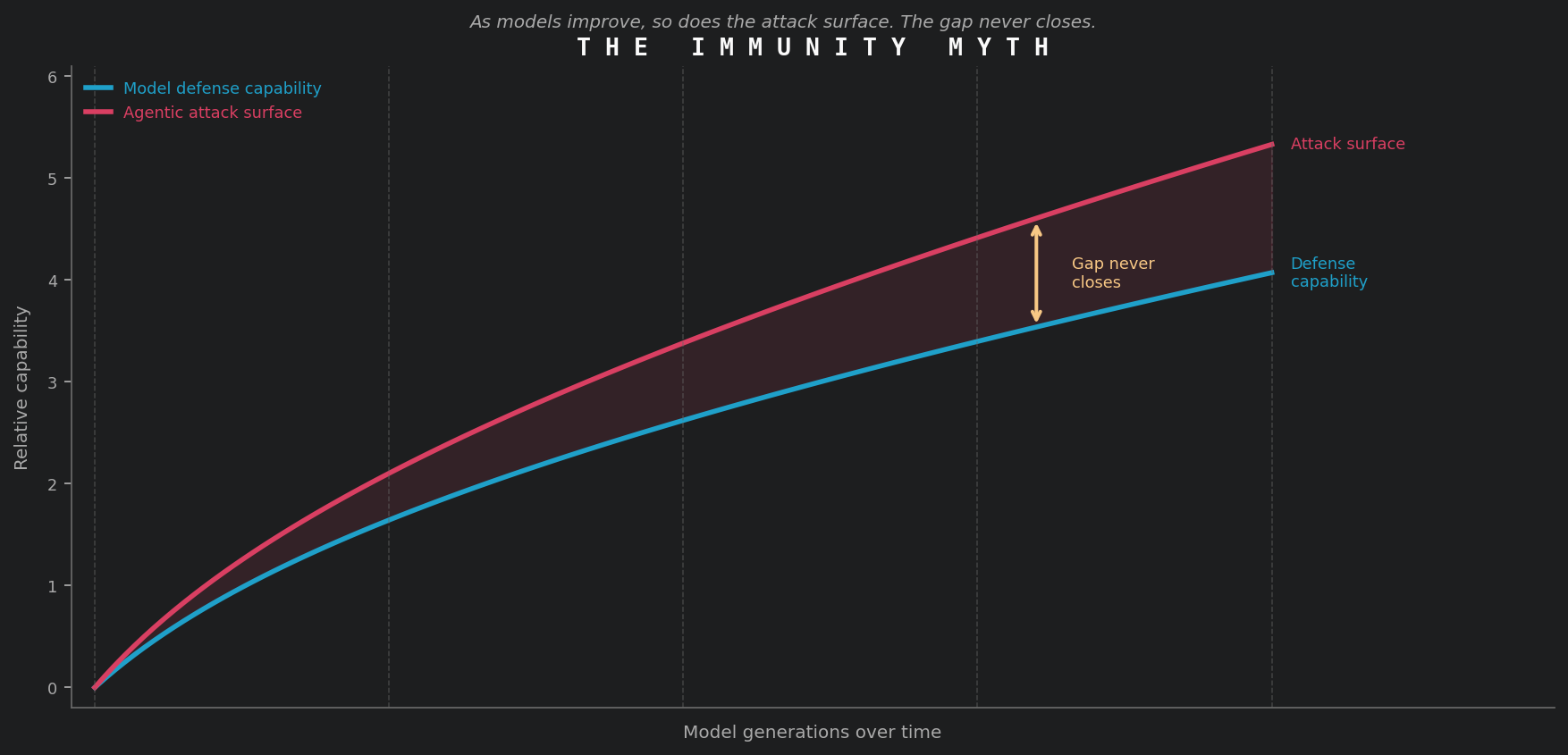
Some coverage of Glasswing raises the question of whether Claude is now immune to prompt injection. The UK's National Cyber Security Centre addressed this directly: prompt injection may never be properly mitigated. OpenAI reached the same conclusion for AI browser agents. The reason is structural: LLMs draw no inherent distinction between data and instruction, making every token a candidate for interpretation as a command. Improving resistance to known injection patterns leaves the underlying structural gap intact.
The deeper dynamic: prompt injection resistance is a contest between a model's reasoning capabilities and an adversary's ability to construct inputs that exploit the gap between what the model understands and what its designers intended. As models grow more capable, they resist known patterns more effectively while also developing new emergent behaviors and broader tool-use capabilities that open new attack surfaces. The defensive surface and the offensive surface expand together, and the gap between them never closes.
Anthropic's own analysis confirms the limits. Despite Mythos Preview's ability to discover thousands of Linux kernel vulnerabilities enabling out-of-bounds writes, the model was unable to successfully exploit any of them for remote attacks because of the kernel's layered defensive architecture. The architecture that works is layered: multiple independent controls operating across the stack, not a single hardened model at the center. The actual lesson from Glasswing is to pair model improvements with independent enforcement layers above them, because one without the other leaves exploitable gaps that compound with every generation.
Glasswing Is a Floor, Not a Ceiling
Anthropic's closing line in the Mythos technical disclosure warrants attention: "The transitional period may be tumultuous regardless." This comes from the team that built the most capable security AI ever documented, and it should be read literally.
The gap between the model generation a defender deploys and the adversarial tools probing it is a moving target. Closing it requires three changes in posture:
Independent runtime enforcement. Runtime protection that reasons with the same model it is protecting can be compromised in the same operation. The enforcement layer needs to be a deterministic, non-LLM safeguard operating outside the model's reasoning chain entirely. The NCSC's specific recommendation aligns here: design protections around mechanisms that constrain system actions from outside the model, because guardrails built inside the model's reasoning are subject to the same vulnerabilities as the model itself.
Continuous adversarial testing. A model that passes a red-team exercise in January may carry new exploitable behaviors in April after fine-tuning, tool updates, or context window changes. A persistent threat requires persistent testing. Straiker's attack and defense agents run continuous adversarial simulation against your agentic stack using the same techniques adversaries deploy, rather than a quarterly checklist that captures a single moment in time.
Visibility into the agentic attack surface. Most organizations have no complete map of which AI agents they run, what tools those agents can access, or what data they can reach. Glasswing-class adversaries will enumerate that surface faster than any manual inventory process. The organizations that map their own AI attack surface before adversaries do are the ones positioned to respond when something changes.
Anthropic's decision to control access, publish their methodology, and commit to responsible disclosure on Mythos reflects exactly the standard the industry should expect from AI labs. Mythos Preview is also the first data point in a trajectory. The organizations treating Glasswing as a ceiling will be underprepared for what follows, because the most capable AI security model ever built still requires external guardrails. That reflects the nature of the problem.
Straiker secures agentic applications across their full lifecycle, discovering your AI agents with Straiker Discover AI, stress-testing them continuously with Straiker Ascend AI, and enforcing runtime protection with Straiker Defend AI. If Glasswing raised questions about your agentic security posture, we'd like to talk.
Anthropic's decision not to release Claude Mythos Preview publicly tells you more about the threat landscape than any benchmark does. Every capability they describe — a 27-year-old OpenBSD flaw found autonomously, a 16-year-old FFmpeg vulnerability that survived five million automated test runs, 181 working Firefox exploits generated in a single session — is also a specification for what a well-resourced adversary is building toward. We believe the Mythos model is being read primarily as a defensive milestone. It should also be read as an adversarial roadmap too.
For context: the model behind Glasswing scored 93.9% on SWE-bench Verified compared to 80.8% for Anthropic's previous flagship, on a benchmark testing real software engineering problems drawn from actual GitHub repositories. That is a fundamentally different capability level, and the discovery-to-exploitation window that once gave defenders weeks or months to respond now collapses to minutes. Project Glasswing deploys this capability defensively before adversaries can match it. The premise is sound. Our view is that the window it assumes is shorter than most security teams think.
The security community's response has been largely admiring: impressive, responsible, necessary. We'd add a fourth word: incomplete.
From APT to AiPT
For two decades, nation-state actors operated under the APT model, where the defining trait was patience: establish a foothold, move laterally, persist quietly, exfiltrate. The rare human expertise required to sustain these campaigns naturally constrained who could run them and at what scale.
AI changes that calculus. Where APT actors relied on expensive human expertise sustained over months, AiPTs — AI-powered Persistent Threats — replace that with autonomous orchestration that runs continuously, adapts in real time, and scales to any target: a new class of AI-driven, agentic cyberattack where autonomous engines plan, adapt, and execute campaigns at scale. The Villager framework our STAR team documented earlier this year is the first confirmed instance in the wild.
Villager, built by the Chinese-based group Cyberspike and published on PyPI, is an AI-native penetration testing framework structured as the successor to Cobalt Strike. For context: it accumulated 10,000 downloads within two months of release, at an average rate of 200 additional downloads every three days during our investigation. It integrates DeepSeek AI with containerized Kali Linux toolsets, uses a database of 4,201 system prompts to generate exploits in real time, and includes 24-hour self-destructing containers with randomized SSH ports to defeat forensic analysis. Any operator can submit a natural language objective and watch the framework decompose it into a full attack chain autonomously.
What Villager and Mythos Preview have in common is more important than what separates them. They represent two points on the same AiPT trajectory: one at the commodity end, one at the frontier. Three behaviors define the class across both:
- Autonomous campaign execution. AiPTs use task-based architectures where the AI decomposes a high-level objective, such as "find and exploit vulnerabilities in example.com," into a full reconnaissance-to-exploitation chain, executes each phase in sequence, recovers from failures, and verifies results without operator intervention. The attacker issues a goal; the framework handles the rest.
- Dynamic, context-driven adaptation. Where Cobalt Strike follows scripted playbooks, AiPTs select and pivot between tools based on what they discover. Villager automatically launches WPScan when it detects WordPress, shifts to browser automation when it finds an API endpoint, and chains results from each step into the next. As Straiker's STAR team noted: "This coordinated approach occurs organically through the GenAI's task planning, not through rigid programming."
- Dramatically lower barrier to entry. Mythos Preview found a FreeBSD remote code execution exploit for under $2,000 and under a day of processing time. Villager achieves multi-stage attack orchestration from a PyPI package anyone can install. The cost and expertise floor for sophisticated attacks is collapsing at both ends of the spectrum.
One detail in Anthropic's technical disclosure ties these two points together: "We did not explicitly train Mythos Preview to have these capabilities. Rather, they emerged as a downstream consequence of general improvements in code, reasoning, and autonomy." Mythos Preview became the most capable offensive AI security tool ever documented without being designed as one. Every future generation will be more capable still. The AiPT trajectory is not a product decision — it is a property of intelligence itself.
When Glasswing-Class Capability Reaches Adversarial Hands
Anthropic has restricted Mythos Preview to a coalition of founding partners spanning cloud infrastructure, enterprise security, and financial services — organizations with the resources and accountability to use it responsibly. That access policy is deliberate and well-considered. Exclusive access to frontier capability is also temporary.
This year, security firm Aisle demonstrated they could replicate Glasswing's vulnerability-finding results using older, publicly available models. Given the investments China, Russia, Iran, and North Korea have made in frontier AI development, Mythos-equivalent capabilities are a near-term certainty in adversarial hands. Three scenarios describe what becomes possible when that happens:
1. Targeting the model layer directly. Organizations deploying Claude or any frontier model in agentic workflows are running a high-value target. Prompt injection spiked 540% in 2025, the fastest-growing threat category in AI security. An adversary needs only one successful injection into your AI agent's context window to access everything that agent can reach. Straiker's own research makes this concrete: a single malicious email can trigger a zero-click agent chain that exfiltrates an entire Google Drive with no user interaction required.
2. Exploiting the agentic stack above the model. Security attention naturally concentrates on the model layer. The agentic applications running above it — tools, memory systems, orchestration layers, integrations — receive far less scrutiny and carry far more exposure. A sophisticated adversary with Mythos-level capability targets the tool-calling layer, the memory interface, or the integration logic, because the model's internal defenses become irrelevant once the attack lives above them.
3. Persistent enumeration of your AI attack surface. An adversary running continuous, low-cost scans against your AI deployment, probing each model update for regression vulnerabilities, is doing something categorically different from a discrete breach attempt. They are tracking a surface that evolves continuously and has never been fully characterized, maintaining a persistent adversarial relationship with your AI infrastructure rather than pursuing a defined exit.
The Immunity Myth
Some coverage of Glasswing raises the question of whether Claude is now immune to prompt injection. The UK's National Cyber Security Centre addressed this directly: prompt injection may never be properly mitigated. OpenAI reached the same conclusion for AI browser agents. The reason is structural: LLMs draw no inherent distinction between data and instruction, making every token a candidate for interpretation as a command. Improving resistance to known injection patterns leaves the underlying structural gap intact.
The deeper dynamic: prompt injection resistance is a contest between a model's reasoning capabilities and an adversary's ability to construct inputs that exploit the gap between what the model understands and what its designers intended. As models grow more capable, they resist known patterns more effectively while also developing new emergent behaviors and broader tool-use capabilities that open new attack surfaces. The defensive surface and the offensive surface expand together, and the gap between them never closes.
Anthropic's own analysis confirms the limits. Despite Mythos Preview's ability to discover thousands of Linux kernel vulnerabilities enabling out-of-bounds writes, the model was unable to successfully exploit any of them for remote attacks because of the kernel's layered defensive architecture. The architecture that works is layered: multiple independent controls operating across the stack, not a single hardened model at the center. The actual lesson from Glasswing is to pair model improvements with independent enforcement layers above them, because one without the other leaves exploitable gaps that compound with every generation.
Glasswing Is a Floor, Not a Ceiling
Anthropic's closing line in the Mythos technical disclosure warrants attention: "The transitional period may be tumultuous regardless." This comes from the team that built the most capable security AI ever documented, and it should be read literally.
The gap between the model generation a defender deploys and the adversarial tools probing it is a moving target. Closing it requires three changes in posture:
Independent runtime enforcement. Runtime protection that reasons with the same model it is protecting can be compromised in the same operation. The enforcement layer needs to be a deterministic, non-LLM safeguard operating outside the model's reasoning chain entirely. The NCSC's specific recommendation aligns here: design protections around mechanisms that constrain system actions from outside the model, because guardrails built inside the model's reasoning are subject to the same vulnerabilities as the model itself.
Continuous adversarial testing. A model that passes a red-team exercise in January may carry new exploitable behaviors in April after fine-tuning, tool updates, or context window changes. A persistent threat requires persistent testing. Straiker's attack and defense agents run continuous adversarial simulation against your agentic stack using the same techniques adversaries deploy, rather than a quarterly checklist that captures a single moment in time.
Visibility into the agentic attack surface. Most organizations have no complete map of which AI agents they run, what tools those agents can access, or what data they can reach. Glasswing-class adversaries will enumerate that surface faster than any manual inventory process. The organizations that map their own AI attack surface before adversaries do are the ones positioned to respond when something changes.
Anthropic's decision to control access, publish their methodology, and commit to responsible disclosure on Mythos reflects exactly the standard the industry should expect from AI labs. Mythos Preview is also the first data point in a trajectory. The organizations treating Glasswing as a ceiling will be underprepared for what follows, because the most capable AI security model ever built still requires external guardrails. That reflects the nature of the problem.
Straiker secures agentic applications across their full lifecycle, discovering your AI agents with Straiker Discover AI, stress-testing them continuously with Straiker Ascend AI, and enforcing runtime protection with Straiker Defend AI. If Glasswing raised questions about your agentic security posture, we'd like to talk.










